Mapping the heavens

This entry will be a quickie, a simple how-to for generating a list of planets from an arbitrary star. There are two methods, both of which require you to use a bit of command line, but nothing too exotic.
Generating a list of planets from a star
Option 1: Hoon one-liner
You can execute this right in your dojo:
- ~sampel-palnet:dojo> `(list @p)`(turn (gulf 0x1 0x5) |=(p=@ (cat 3 ~matwet p)))
Replace ~matwet with the star of your choice. You can also change the 0x5 to a different number to generate a longer list than 5 – e.g, 0x10 would give you a list of 10. Note that this generates a list ‘from zero’ – it will always generate the same list, given the same input.
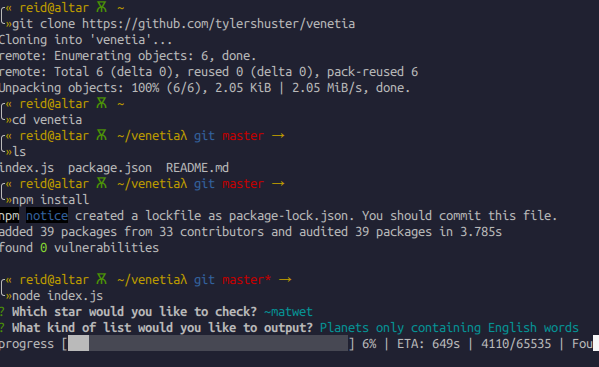
Option 2: Venetia
There is also a fabulous little Node package by tylershuster (~radbur-sivmus) for generating a list of all planets issuable by a star and save it to a file. It’s very easy to use:
- $> sudo apt install npm
- $> git clone https://github.com/tylershuster/venetia
- $> cd venetia
- $> npm install
- $> node index.js
You’ll be prompted to choose one of three options – all planets, all planets with english-ish words, and planets with only english-ish words. It will take a few minutes to churn through all of them!
Once completed, you’ll find a text file inside the same folder named planets.txt.
Update: You can now use Venetia as a webapp without installing Node, and find homophones for English words.
Update 2: ~hadnex_samzod adds the following:
Python script to print all english (american) words using the linux installed dictionary in /usr/share/dict/american:
import subprocess
# Change me
the_dict = "/usr/share/dict/american"
command = ["egrep", "-w", "^\w{6}$", the_dict]
prefix = [ 'bac', 'bal', 'ban', 'bar', 'bat', 'bic', 'bid', 'bil', 'bin', 'bis',
'bit', 'bol', 'bon', 'bor', 'bos', 'bot', 'dab', 'dac', 'dal', 'dan', 'dap',
'dar', 'das', 'dat', 'dav', 'dib', 'dif', 'dig', 'dil', 'din', 'dir', 'dis',
'div', 'doc', 'dol', 'don', 'dop', 'dor', 'dos', 'dot', 'dov', 'doz', 'fab',
'fad', 'fal', 'fam', 'fan', 'fas', 'fid', 'fig', 'fil', 'fin', 'fip', 'fir',
'fit', 'fod', 'fog', 'fol', 'fon', 'fop', 'for', 'fos', 'fot', 'hab', 'hac',
'had', 'hal', 'han', 'hap', 'har', 'has', 'hat', 'hav', 'hid', 'hil', 'hin',
'hob', 'hoc', 'hod', 'hol', 'hop', 'hos', 'lab', 'lac', 'lad', 'lag', 'lan',
'lap', 'lar', 'las', 'lat', 'lav', 'lib', 'lid', 'lig', 'lin', 'lis', 'lit',
'liv', 'loc', 'lod', 'lom', 'lon', 'lop', 'lor', 'los', 'mac', 'mag', 'mal',
'map', 'mar', 'mas', 'mat', 'mic', 'mid', 'mig', 'mil', 'min', 'mip', 'mir',
'mis', 'mit', 'moc', 'mod', 'mog', 'mol', 'mon', 'mop', 'mor', 'mos', 'mot',
'nac', 'nal', 'nam', 'nap', 'nar', 'nat', 'nav', 'nib', 'nid', 'nil', 'nim',
'nis', 'noc', 'nod', 'nol', 'nom', 'nop', 'nor', 'nos', 'nov', 'pac', 'pad',
'pag', 'pal', 'pan', 'par', 'pas', 'pat', 'pic', 'pid', 'pil', 'pin', 'pit',
'poc', 'pod', 'pol', 'pon', 'pos', 'rab', 'rac', 'rad', 'rag', 'ral', 'ram',
'ran', 'rap', 'rav', 'rib', 'ric', 'rid', 'rig', 'ril', 'rin', 'rip', 'ris',
'rit', 'riv', 'roc', 'rol', 'ron', 'rop', 'ros', 'rov', 'sab', 'sal', 'sam',
'san', 'sap', 'sar', 'sat', 'sav', 'sib', 'sic', 'sid', 'sig', 'sil', 'sim',
'sip', 'sit', 'siv', 'soc', 'sog', 'sol', 'som', 'son', 'sop', 'sor', 'sov',
'tab', 'tac', 'tad', 'tag', 'tal', 'tam', 'tan', 'tap', 'tar', 'tas', 'tic',
'tid', 'til', 'tim', 'tin', 'tip', 'tir', 'tob', 'toc', 'tod', 'tog', 'tol',
'tom', 'ton', 'top', 'tor', 'wac', 'wal', 'wan', 'wat', 'wic', 'wid', 'win',
'wis', 'wit', 'wol', 'wor' ]
suffix = [ 'bec', 'bel', 'ben', 'bep', 'ber', 'bes', 'bet', 'bex', 'bud', 'bur',
'bus', 'byl', 'byn', 'byr', 'byt', 'deb', 'dec', 'def', 'deg', 'del', 'dem',
'den', 'dep', 'der', 'des', 'det', 'dev', 'dex', 'duc', 'dul', 'dun', 'dur',
'dus', 'dut', 'dux', 'dyl', 'dyn', 'dyr', 'dys', 'dyt', 'feb', 'fed', 'fel',
'fen', 'fep', 'fer', 'fes', 'fet', 'fex', 'ful', 'fun', 'fur', 'fus', 'fyl',
'fyn', 'fyr', 'heb', 'hec', 'hep', 'hes', 'het', 'hex', 'hul', 'hus', 'hut',
'leb', 'lec', 'led', 'leg', 'len', 'lep', 'ler', 'let', 'lev', 'lex', 'luc',
'lud', 'lug', 'lun', 'lup', 'lur', 'lus', 'lut', 'lux', 'lyd', 'lyn', 'lyr',
'lys', 'lyt', 'lyx', 'meb', 'mec', 'med', 'meg', 'mel', 'mep', 'mer', 'mes',
'met', 'mev', 'mex', 'mud', 'mug', 'mul', 'mun', 'mur', 'mus', 'mut', 'myl',
'myn', 'myr', 'neb', 'nec', 'ned', 'nel', 'nem', 'nep', 'ner', 'nes', 'net',
'nev', 'nex', 'nub', 'nul', 'num', 'nup', 'nus', 'nut', 'nux', 'nyd', 'nyl',
'nym', 'nyr', 'nys', 'nyt', 'nyx', 'pec', 'ped', 'peg', 'pel', 'pem', 'pen',
'per', 'pes', 'pet', 'pex', 'pub', 'pun', 'pur', 'put', 'pyl', 'pyx', 'reb',
'rec', 'red', 'ref', 'reg', 'rel', 'rem', 'ren', 'rep', 'res', 'ret', 'rev',
'rex', 'ruc', 'rud', 'rul', 'rum', 'run', 'rup', 'rus', 'rut', 'rux', 'ryc',
'ryd', 'ryg', 'ryl', 'rym', 'ryn', 'ryp', 'rys', 'ryt', 'ryx', 'seb', 'sec',
'sed', 'sef', 'seg', 'sel', 'sem', 'sen', 'sep', 'ser', 'set', 'sev', 'sub',
'sud', 'sug', 'sul', 'sum', 'sun', 'sup', 'sur', 'sut', 'syd', 'syl', 'sym',
'syn', 'syp', 'syr', 'syt', 'syx', 'teb', 'tec', 'ted', 'teg', 'tel', 'tem',
'ten', 'tep', 'ter', 'tes', 'tev', 'tex', 'tuc', 'tud', 'tug', 'tul', 'tun',
'tus', 'tux', 'tyc', 'tyd', 'tyl', 'tyn', 'typ', 'tyr', 'tyv', 'web', 'wed',
'weg', 'wel', 'wen', 'wep', 'wer', 'wes', 'wet', 'wex', 'wyc', 'wyd', 'wyl',
'wyn', 'wyt', 'wyx', 'zod', ]
# Load 6 letter dictionary words into list
process = subprocess.Popen(command, stdout=subprocess.PIPE)
stdout_data, stderr_data = process.communicate()
# Convert to set for fast lookup
words = set(stdout_data.decode('utf8').splitlines())
for i in prefix:
for j in suffix:
urbit_word = i+j
if urbit_word in words:
print(urbit_word)
This post is also available on Urbit, where you can post comments. Join ~matwet/networked-subject and open the Networked Subject notebook. Boot a free comet or Buy a planet with Bitcoin .
.