%graph-store: Social-optimized graph database

For a few months, a new piece of architecture has been quietly added to Urbit. A component called %graph-store has been rolled out to replace the bespoke databases previously used by the chat, publish, and link collection apps. The design and development of %graph-store was spearheaded by ~tacryt-socryp, a Tlon employee.
In brief, %graph-store is a flexible, interoperable database format purpose-built to accomodate social software. It’s urbit-native, but can be programmed and queried externally like any other database.
You can watch a recent community discussion stream here; this post was distilled from ~tacryt’s presentation and the proposal document he sent out to the urbit-dev mailing list.
Graph databases
In order to give a deeper description, it is helpful to establish what a graph database is; I find that one of the best ways to understand something is to compare it to something different but related. So to begin, a bite-sized explanation of relational databases.
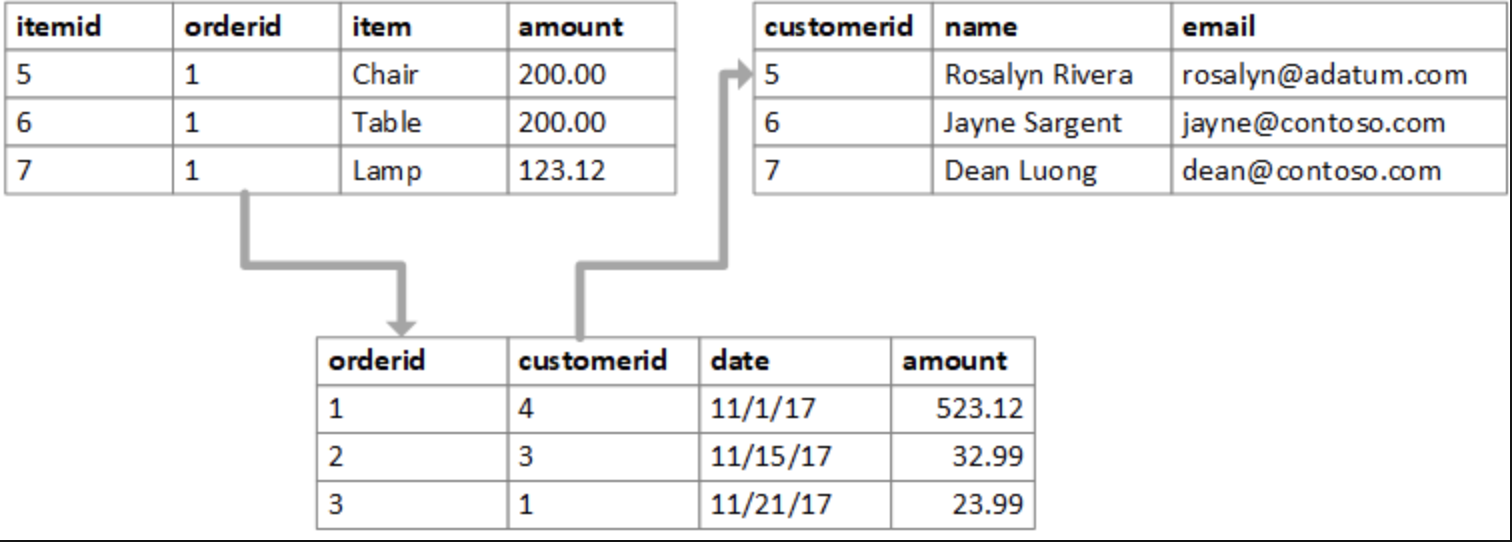
- a representation of a relational database
If you’ve written any SQL, you already have an idea of what a relational database is. This is what most people mean when they say database – a collection of tables containing a list of items and their associated attributes, where one can generate new tables by querying their contents. It is basically a spreadsheet you program to spit out other spreadsheets.
Relational databases are most useful for highly structured data, like a phonebook. They are not optimized for relating a list of many things to another list of many things – eg, generating a Kevin Bacon-style list of who-knows-who. They can do these things, but not efficiently, and with exponentially more difficulty as scale increases.

- an analog implementation of a graph database
Graph databases are a more recent innovation that have become very popular and powerful in the last couple of decades, thanks in part to their utility in modeling human relations and interactions. In a graph database, items are ‘nodes’, and are connected to other items with ‘edges’ (or ‘relationships’). That is to say, the relationship between two pieces of data is explicit, stored as its own piece of data, and not something that has to be defined and looked up in another table. This makes it much more efficient to work with pieces of data that are connected in complex ways.
%graph-store
In order to think about what kind of database would be useful for social software content, it helps to step back and think of what exactly social software does abstractly; a reasonable answer is that it allows users to assume an identity to post text or media in a threaded, chronological format. Everything from 4chan to Twitter to Discord is some variation of this basic function with various bells, whistles, and constraints.
%graph-store is a data structure meant to accommodate the data generated by this kind of digital social activity. In the linked presentation, ~tacryt mentions targeting Twitter’s functionality with %graph-store because minus the character limit, it’s the most flexible of the major social media services in terms of how content can be threaded. Most other modes of social content – forums, blog posts + comments, chats – could be whittled out of the Twitter format.
%graph-store runs as a Gall application in userspace, acting as a database microservice. Applications can interact with it with commands (%poke), queries (%peek), or subscriptions (%watch). Other applications perform all of their operations on data with these basic functions.
Under the hood, %graph-store graphs are trees of nodes numbered in descending order. This is an optimization for displaying the most recently appended content first, which is typical of social applications. Nodes contain a post, as well as another graph. That graph can either be empty, or contain the node’s children – i.e. its replies.
Since Nock only understands binary trees, these graphs don’t have cycles like other graph databases, but rather ‘virtual cycles’ where any node can refer to any other node.
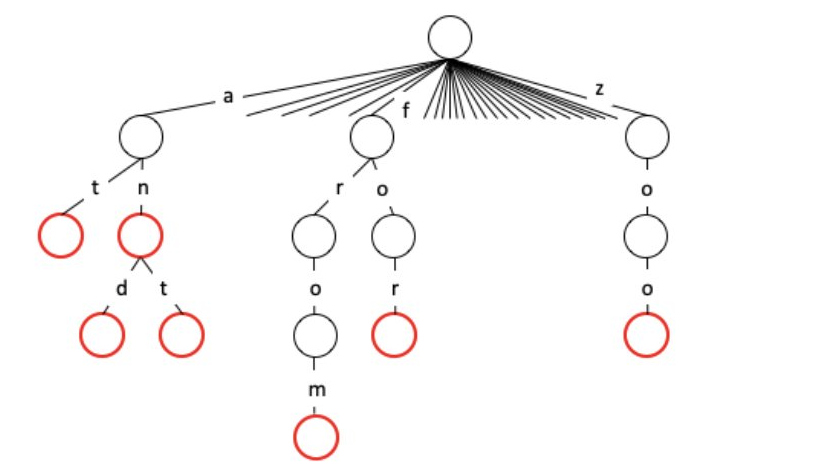
- image taken from ~tacryt’s presentation
A post itself contains a list of contents, metadata, a truncated hash of the post’s noun, and signatures. The contents of the post can contain text, mentions (which hook into the notification system), URLs, executable code(!), and references to other nodes. ~tacryt also mentions future plans for supporting dynamic data content.
As a result of having a hash and signatures, all posts are cryptographically attested, not just by the post but by its children. This means that data cannot be deleted, only appended, and that you can be certain of the validity of the content. Urbit’s strong type system also means that data stored in %graph-store is always strongly validated.
This collection of traits is unique and powerful; it also acts as a fundamental structure that can be shared by many types of software. For example, the chatting and blogging apps within Urbit both make use of it, only applying different semantics to the content of the graph. New uses are as simple as creating a new validation schema. Cryptographic validation opens up new possibilities for what posts can do, by offering blockchain-style security and legally legible guarantees.
Most interesting to me is the possibility of collating graph content across apps; no longer will your tweets need to be siloed from your essays or music playlists. The social data you generate across disparate services will truly be a single corpus of content – one big database you can pick up and take with you, and one that actually belongs to you, even in a cryptographically verifiable sense.
%graph-store is not just limited to applications running on Urbit; Urbit has an an HTTP API with implementations in JS, Go, and Python. External clients can take advantage of it without having to program any Hoon – one could build e.g. a graph explorer application in Python, or forum webapp in JS, which interact with your graph data by querying through Airlock, Urbit’s API.

When I describe Urbit to people, I always find myself using the metaphor of a Katamari picking up all the pieces of technology spread across other peoples' servers and hooking them into each other on your behalf; %graph-store reflects and extends this. It’s exciting to consider what new kind of technology might come of it.
External links
Proposal document – https://docs.google.com/document/d/1-Gwfg442kV3cdfG7NnWPEf2TMa3uLUTAKkZD70ALZkE/edit
Developer Call presentation – https://www.youtube.com/watch?v=E4DFuAZQ32Y
This post is also available on Urbit, where you can post comments. Join ~matwet/networked-subject and open the Networked Subject notebook. Boot a free comet or Buy a planet with Bitcoin .
.